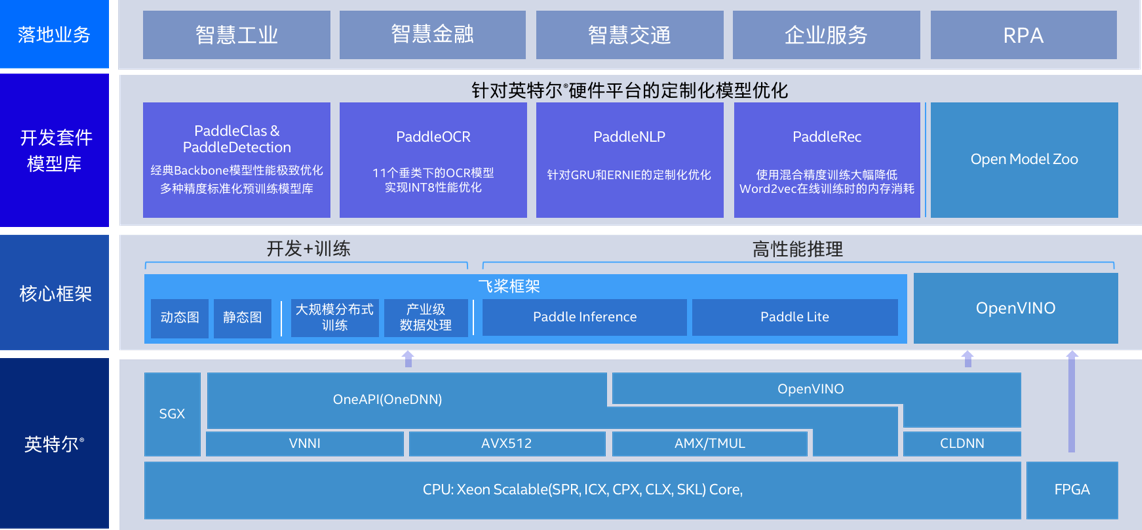
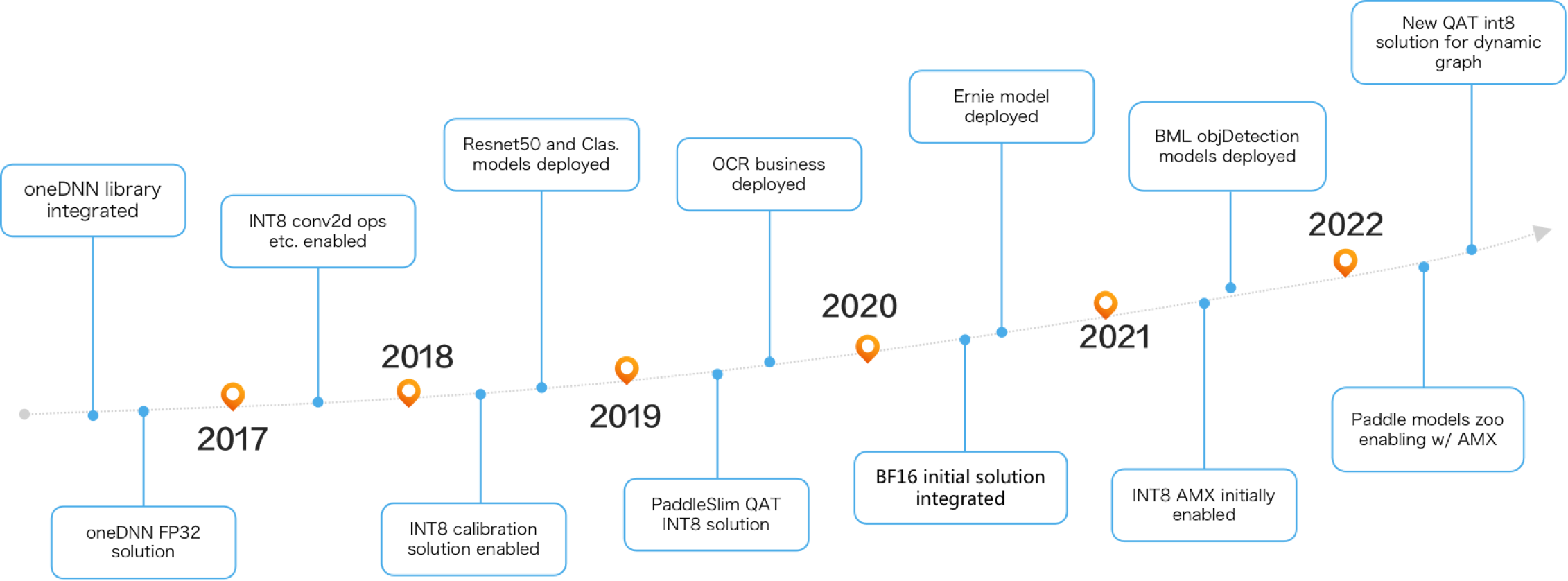
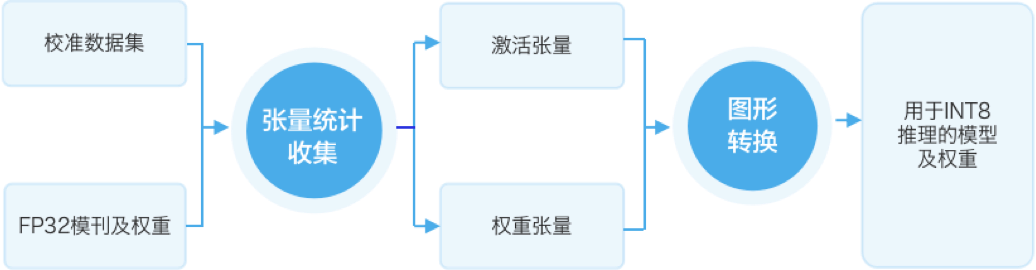
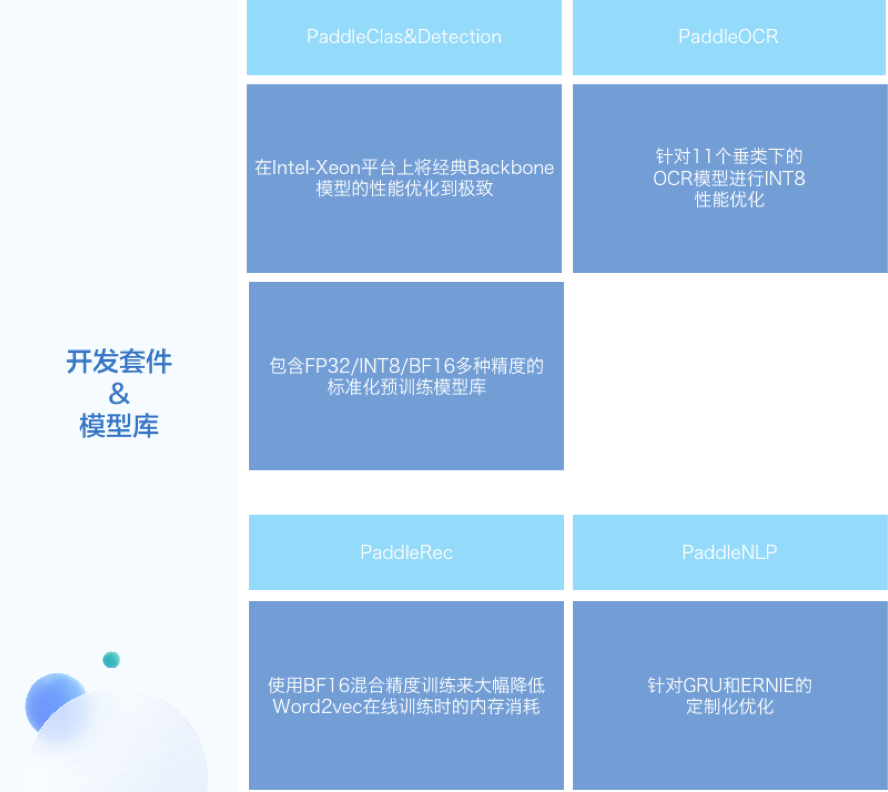
飞桨 x OpenVINO™ 介绍
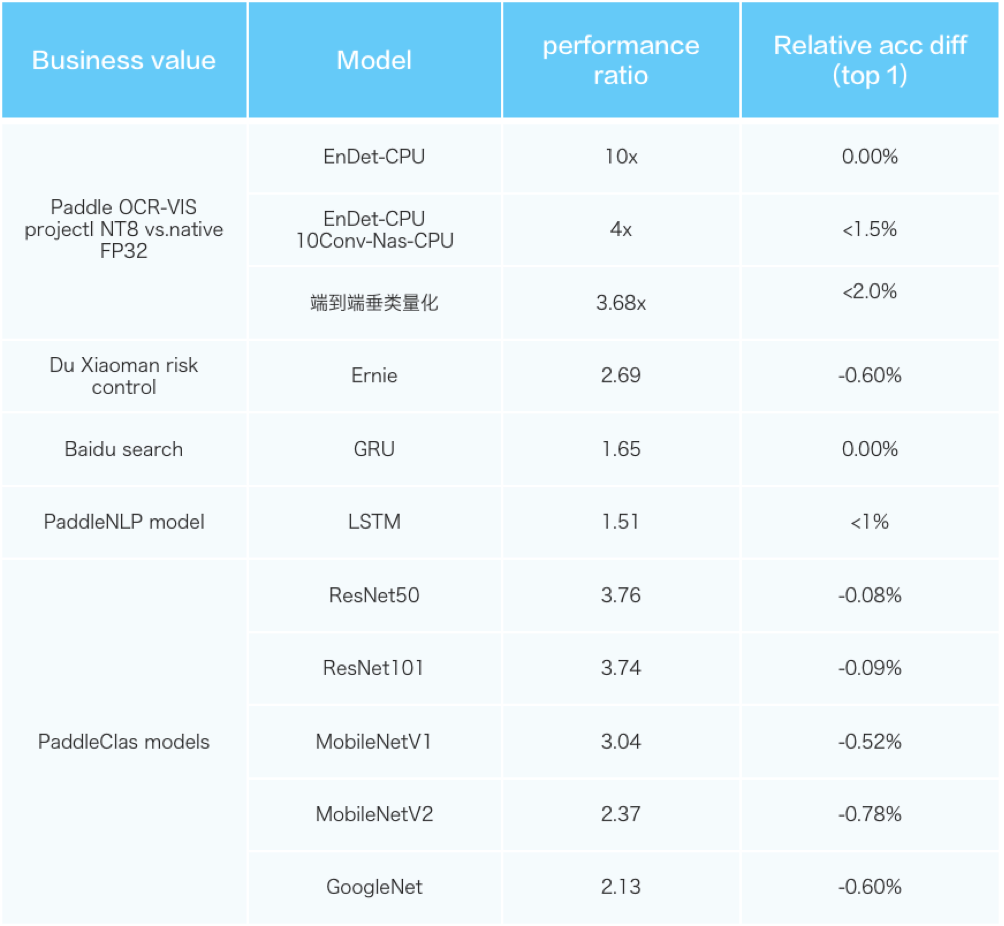
飞桨平台训练产出的模型,目前已经支持使用OpenVINO™ 直接进行推理加速;基于此能力,我们为开发者打造了基于飞桨核心训练框架、模型库和优化工具,以及OpenVINO™
工具套件的全流程开发部署方案,开发者可以使用飞桨进行便捷的模型开发,而后无缝迁移至OpenVINO在Intel平台上实现高性能部署
未来,我们还会加入更广泛的算子覆盖,并支持量化模型等模型特性;飞桨团队也正在尝试将OpenVINO™
作为后端直接接入飞桨端侧推理引擎Paddle Lite中,介时开发者的使用体验可得到进一步优化

支持70+飞桨原生算子

覆盖大多数常见模型

支持控制流等复杂模型结构
关于英特尔® OpenVINO™ 工具套件
- 人工智能推理将应用神经网络训练后获得的功能,以取得结果。英特尔® OpenVINO™ 工具套件可支持您运用附带的模型优化器和运行时及开发工具, 来优化、调优和运行全面的人工智能推理。
OpenVINO™ 工具套件优化策略
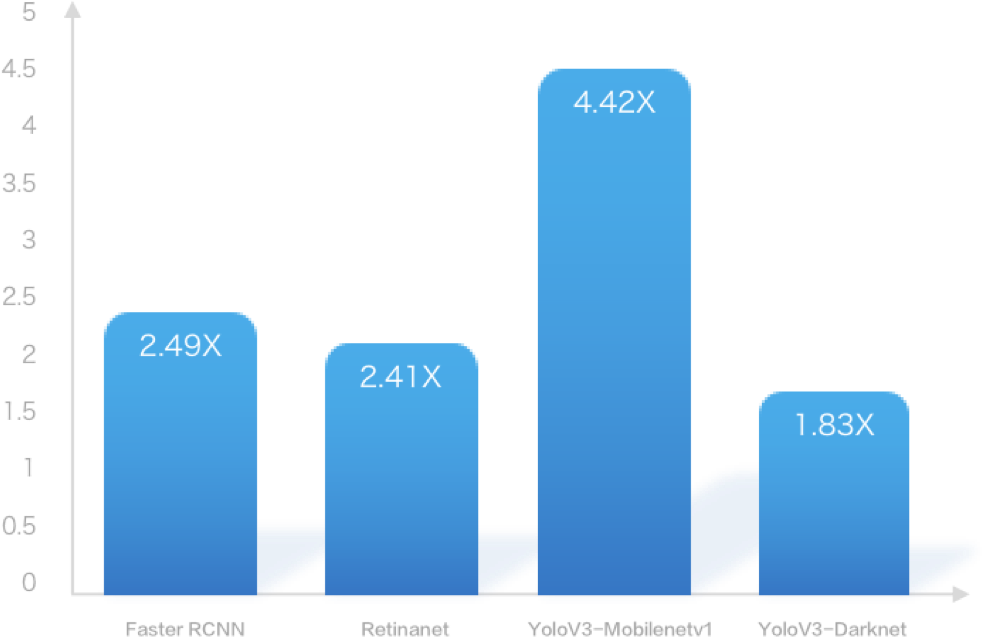
- 针对复杂网络的模型结构压缩技术
- 针对多任务场景的跨平台异构加速技术
- 基于 oneAPI 的 NN 加速引擎
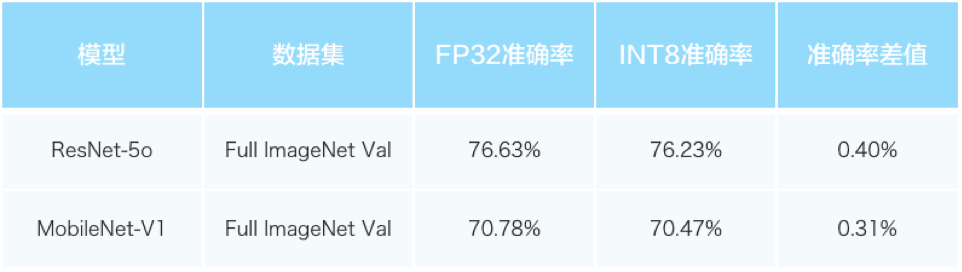
- 面向低比特混合精度的量化与模型重训练策略

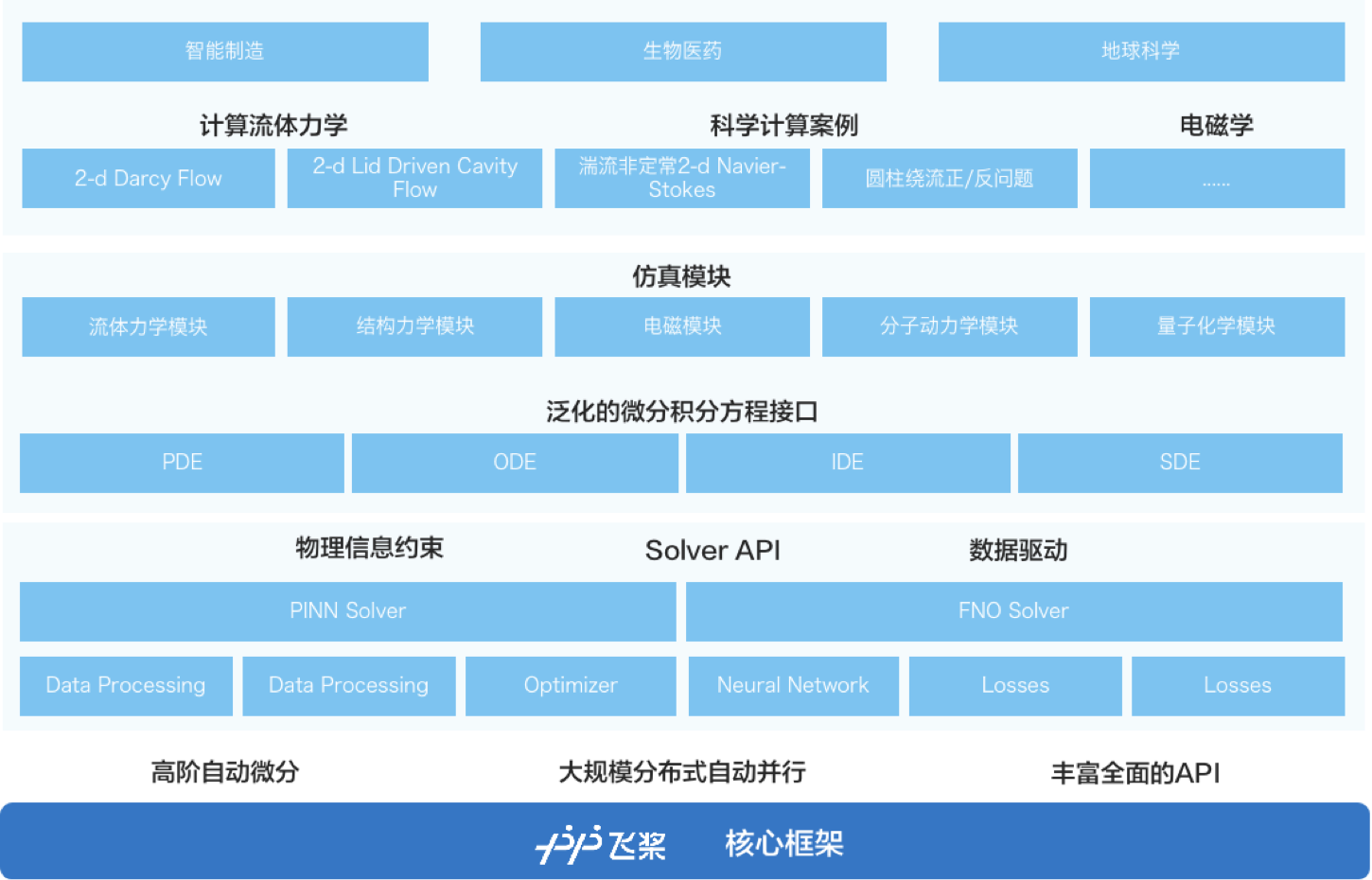
丰富的模型选择

海量的实践教程
课程共建
EasyDL+OpenVINO™ 课程专区